
Executives behind Summly, the startup that was sold to Yahoo for $30 million in 2013, announced their latest venture, Cosmify, a knowledge discovery platform. Investors in the company include Bart Swanson, ex-Chairman and President at Summly, Ross Mason, Founder and VP, Product at Mulesoft, and Leonid Igolnik, VP, Engineering at CA Technologies.
"Organizations and teams collect too much data to store or to analyze. Unstructured data like documents, images, emails, and videos and structured data like tables, and sheets make up the majority of data that is stored these days" said Ross Mason. "With Cosmify, Eugene Ciurana, Founder and CEO, and team have built a platform that integrates unstructured and semi-structured data, provides advanced discovery and analysis capabilities, enables knowledge management, and facilitates secure collaboration" adds Ross.
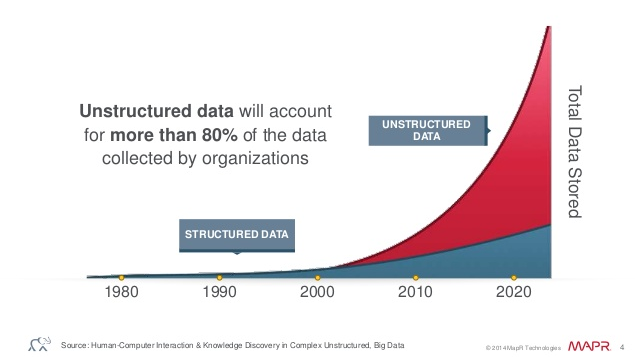
According to IDC, a market research firm, the volume of digital data will grow 40% to 50% per year. by 2020, IDC predicts the number will have reached 40,000 EB or 40 Zettabytes (ZB).
Cosmify can address a wide variety of analysis and knowledge discovery problems that organizations face when dealing with unstructured and semi-structured data. "Existing players in the market are too expensive or take a long time to provide relevant results. We have found a fantastic balance between relevance, cost, and time - essentially being far more efficient than other machine learning platforms out there" says Eugene Ciurana.
One inspiration for Cosmify came from the mundane task of preparing taxes. "I had an epiphany. I had always painstakingly organized my invoices, but I realized I simply needed the ability to find an invoice if there was a query about it. My perspective switched from 'how organized can I be' to 'how effectively can I search', a lesson from the rise of internet search engines which we should be applying to our personal data. We built Cosmify as a platform to let everyone search and extract knowledge from their own documents with the assistance of machine learning" says Ana Nelson, Co-Founder and Chief Science Officer.
Cosmify initially plans to target cloud based service providers with its service. "Cloud based services are dealing with unprecedented amounts of data and we know Cosmify can add so much value by removing the guesswork from their decision making" adds Eugene. Cosmify currently has 5 employees and is based in San Francisco. The team includes Connor Goodwolf, DevOps, ex-Summly, and Patrick Twohig, software engineer.
I spoke to Eugene, CEO and Founder, to find out more about Cosmify.
S: What's your background prior to Cosmify?
E: I realized in 2009 or 2010 that smart companies were changing their focus from high performance systems to leveraging data. Most of the 2000-2010 decade was about system throughput. That problem was well understood by 2009 or so, and the range of solutions has matured, so the next step was to extract information and knowledge from the huge amount of data that those systems collect. High throughput systems handle larger work loads that deluged companies with data.
My personal evolution went from applying classical and Bayesian statistical analysis methods using Map/Reduce and Hadoop, to multivariate analysis, and more exotic analytics. As complex as the math can be, these applications are somewhat straight forward to implement because they operate on structured data.
Next, I spent over 2 years as CTO at Badoo, the most profitable dating service in the world and the largest in Europe and Latin America. One of my main concerns was the implementation of a Business Intelligence system for analyzing user profiles, subscriber photos, and payment lifecycle determine which users were good customers, which ones might have fake accounts or needed to be weeded out because they were selling adult services instead of hooking up or dating, calculate customer half life, and so on. Our BI systems dealt with a combination of structured and unstructured data, and 75% of the work was algorithmic, with a bit of machine learning thrown in for chat logs analysis.
Next up, I was the CTO at Summly. Just a bit of traditional stats (via FlurryAnalytics), where the bulk of the work was Natural Language Processing and Summarization. This required building a system trained to summarize content by resolving document length, scoring coherence, and synthesizing text from a base document. Pure machine language applied to high volume document extraction and analysis. Summly got acquired by Yahoo in 2013.
Yahoo was a superset of Summly. In addition to automatic summarization, I was involved in crawling sites like Wikipedia and similar unstructured data sources to build a semantic knowledge graph that associates people, events, and concepts.

S: What inspired you to start Cosmify?
E: It was an evolutionary process. Between 2008 and 2014 I went from implementing Hadoop and numerical data analysis for investment banks and government agencies to deploying high volume Natural Language processing, Summarization, and Semantic Analysis systems across the various applications my teams built for my employers or clients during that period. I had an epiphany in 2014 - the technological and business processes around this are reproducible, can be optimized and automated, and don't require every Big Data and Knowledge Discovery system to be a huge undertaking. Data analysis can be packaged and democratized.
All these experiences combined made me realize that anyone doing unstructured data analysis faced the same challenges: crawl the data source, extract and clean up the relevant nuggets, build a database with those concepts leveraging an underlying graph topology, and apply data analysis techniques to extract actionable knowledge from the data. Cosmify is based on these experiences and implements all these aspects of the analysis process.
S: So, what does Cosmify do?
E: The Cosmify platform enables regular people to explore large bodies of unstructured data (documents, images, conversations, social media feeds) without having to worry about how to get the data into the system or how to apply the math and algorithms to get meaningful output. Cosmify produces actionable results that support business processes, legal discovery, HR candidate identification, and other useful tasks without spending a fortune in data analysis shamans' professional services, and without investing in expensive software and server infrastructure.
S: What is Cosmify's unique selling point?
E: In one word: SIMPLICITY. Our system goes to the data sources and extracts the data in whatever format it exists without user participation. It exposes the operations that can be performed on the data through a simple language interface and a dashboard. All analysis activities are done by pointing-and-clicking. The results are presented on screen, and can be exported to email or even instant messages with a single click. A paralegal can use the system to find documents that meet some criteria. Insurance adjustors can click their way through a claim and the system will tell them if fraud is suspected and why.
IBM's Watson requires someone to bring the data into the system. Microsoft's Azure Machine Learning is useless without data science and programming skills. Robust products like Palantir carry a high license cost, take a long time to roll out, and results depend on paying for professional services through the nose to bring some data shamans that will make the system work. Lawyers and business analysts may either lack the budget or lack the skills to build something like this.
S: How did you and Ana, your Co-Founder, meet?
E: I kicked around the idea of Cosmify for about 4 months after I left Yahoo. I'm not a scientist; I'm a computer engineer. I lack some of the data analysis background to pull what I wanted to build off, so I asked around and met with a long list of scientists in the Bay Area, Japan, China, and Russia. A friend and famous Python guru (the Python language is one of pillars of exploratory data analysis; R is the other) introduced me to Ana - she has tremendous programming chops and is a well known scientist specialized in reproducible research. She liked the idea of creating an unstructured data analysis system that anybody could use. Turned out too that we have common friends working at Trinity College in Dublin, where she earned her PhD and where I lectured a few times as a guest speaker about advanced large systems programming. She's young and has shown more skill and insight than the quants and data scientists with whom I worked in the last few years. We figured that we complement each other's skills well, and next thing you know she's co-founding the company.

S: What are the advantages of using Cosmify?
E: Cosmify competes well against other platforms because it provides relevant and accurate results comparable to those of much costlier options, combined with the simplicity of an end user product offering.
- Enabling regular people who aren't data shamans, math gurus, or rockstar engineers to get timely, relevant results is one of our key differentiation factors. Users can benefit from using Cosmify in as little as 15 minutes after installing the stand-alone app. No other system on the market offers this level of turnkey functionality.
S: What's your ecosystem like?
E: Most platforms in the market today can be classified in two large groups: enterprise, high volume unstructured data analysis, and web sentiment analysis.
Enterprise-class unstructured data analysis have a very high total cost of ownership, long learning curves, and steep adoption curves. They are the kinds of applications that the federal government would use for knowledge discovery, and while they offer very high results relevance, the cost per result is also very high. Palantir and Skytree are good examples of these. IBM Watson is another, but not because Watson itself is expensive but because, to make it useful, an IBM customer must pay a fortune in professional services to get the system to work.
The web sentiment analysis platforms crawl web or are built around web crawling and data collected from mobile applications. They provide insights about specific topic ranges and are often complemented by inputs from curated document services like Lexis/Nexis or from company-based internal data sources. They are much easier to use than enterprise platforms, and they have a user-centric approach to information extraction. Companies in this space often have a self-serve, pay as you go model. Quid, Dataminr, Meltwater fall into this category.
S: What are structured, semi-structured, and unstructured data?
E: Structured data has a high degree of organization, every record of some kind has identical layout to every other record of the same kind, and search and analysis are straight forward since every record is the same as any other. Only the attributes of each record are different (e.g. name of a person, SSN, whatever). Unstructured data is the exact opposite (e.g. free form text like emails or a novel; the image captured in a photograph).
Semi-structured data lies somewhere in between. Things like address books, calendar entries, Tweets and other social media streams have some level of structure in how the data are organized. The structure isn't consistent, and there can be great variability between records. For example: an address book may have consistent fields structure for basic information, but the value of something like "address" has a lot of variability. The address data often reflects international addresses. House number first, or last. Non-Latin character sets. Many modern applications allow attaching photos or other media to an address book entry, and so on.
Disclaimer: I'm an investor and advisor to this company.