In web development, as in life, sometimes we develop patterns in how we think about a topic or achieve a common task. This is necessary, as to do otherwise would waste a lot of mental cycles on trivial problems we've already solved. However, these patterns can be hard to break, even when perhaps the pattern is no longer the optimal solution.
One of the most common tasks a front-end developer may handle is traversing the DOM (Document Object Model). Usually this involves locating a DOM element and then manipulating it and/or its contents. Most of us have been using jQuery for this task for the past seven or eight years, as it is one of the core things jQuery has handled well since day one.
In "Internet time" though, seven years is forever. Back in 2006, when jQuery was initially released, Flash was hot and and Rich Internet Applications built with Flex or Silverlight or even Laszlo seemed like they might be the future of the web. Who needs the DOM when plugins were the future of web development.
The point is, a lot has changed. The browser can now handle DOM traversal in ways that weren't possible when jQuery was invented. Plus, new libraries have come along that offer a totally different approach to DOM traversal than the one we've grown so accustomed to. So, it seems like a fair time to ask, do we even need jQuery for DOM traversal anymore?
How We Usually Do DOM Traversal
Before we explore the native methods available or alternative libraries. It's useful for us to first remind ourselves of what the common DOM traversal methods that come with jQuery are, so that we know what it is we'll need to replace.
Selectors
Of course, the first thing we need are some selectors. jQuery offered a CSS-like syntax for selecting DOM elements, which helped make it feel comfortable. Here are some simple selectors:
$(".fancybutton") // select an element with a class of "fancybutton"
$("li:even") // select the even numbered items in a list
Most readers are probably already comfortable with the basics of selectors in jQuery. Once you've selected a DOM element, you can begin travering from that point - so let's look at the typical DOM traversal methods.
DOM Traversal Methods
Before we begin exploring the various DOM traversal methods, it may be useful to have a simple DOM to work with, that way we can clearly illustrate what each method would do.
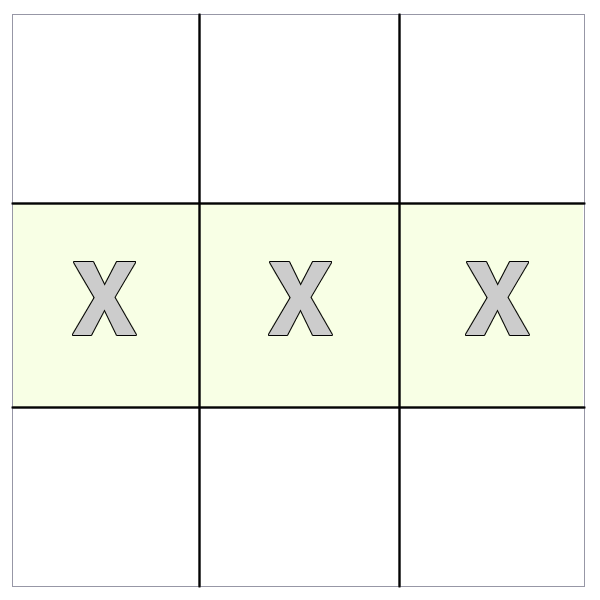
Our example is trivial, but this simple table of three columns and three rows makes it easy to visualize what we are selecting. Below are the most commonly used DOM traversal methods along with an illustration showing what they would select.
Note: In the illustrations, the highlighted element is the DOM node that is selected via the selector and the X's indicate the nodes selected by the traversal method.
siblings()
The method gets the sibling elements (i.e. DOM nodes with the same immediate parent element) of the selected node. In the case of a table cell, that would return the other adjoining cells.
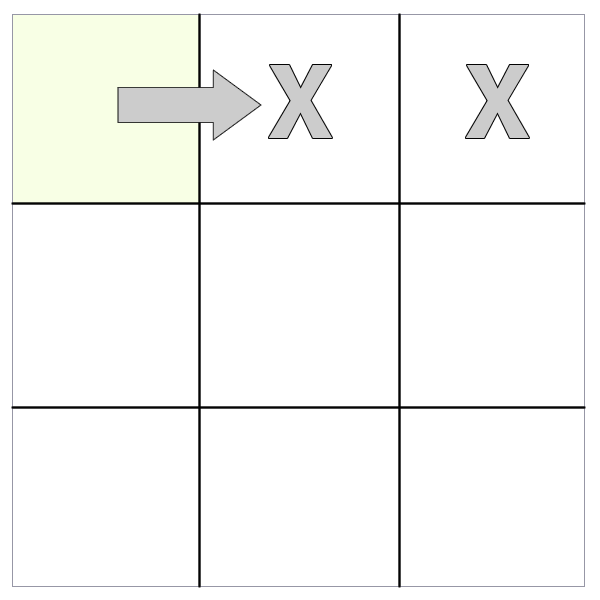
In the case of a row, this would return the other rows.
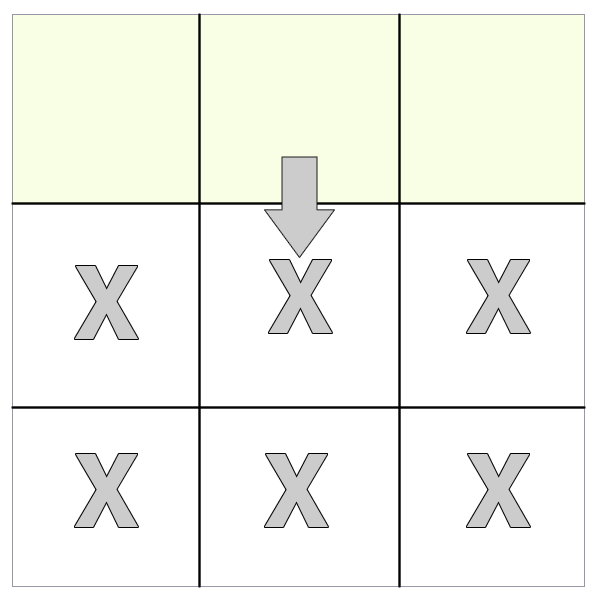
parent() and parents()
The method returns the immediate parent node of the selected DOM node. Thus, for a cell it would return the row parent.
For a row, it would return the table parent.

The method returns all parents for the selected node all the way up the dom tree. Thus, for a cell it would return the row and the table (technically speaking, it will also return the body and the html nodes but for the purposes of the illustration, I've left those out).
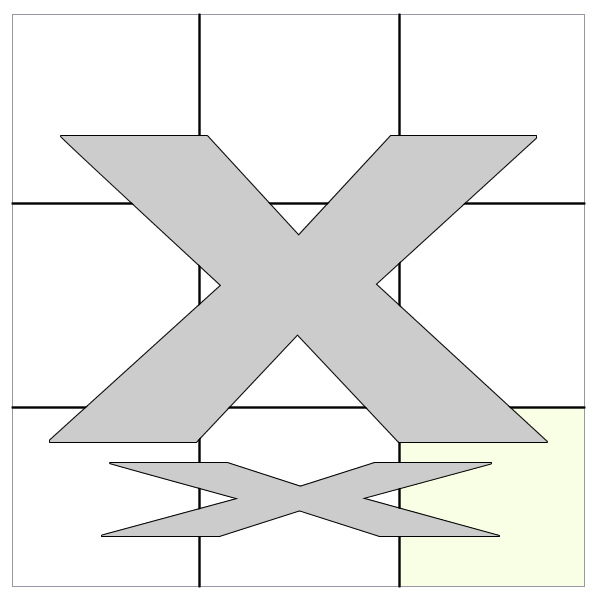
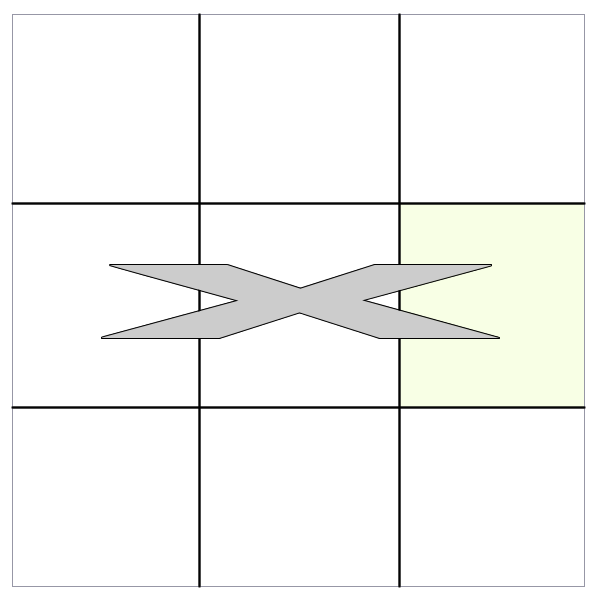
next() and nextAll()
The method returns the sibling that immediately follows the selected node. For instance, if we select a cell, it would return only the next cell in the same row.
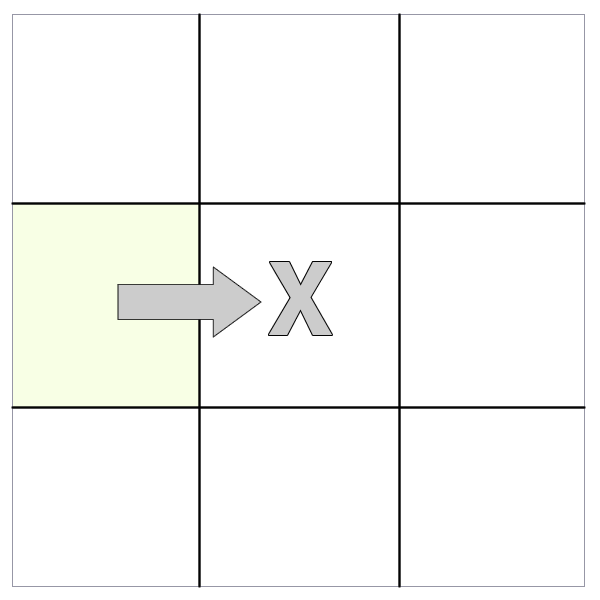
However, would return all of the subsequent cells that follow. This differs from in that it does not return any siblings that precede the selected DOM node.

prev() and prevAll()
The 'prev()' and 'prevAll' methods work identically to 'next()' and 'nextAll()' except they select the preceding siblings.
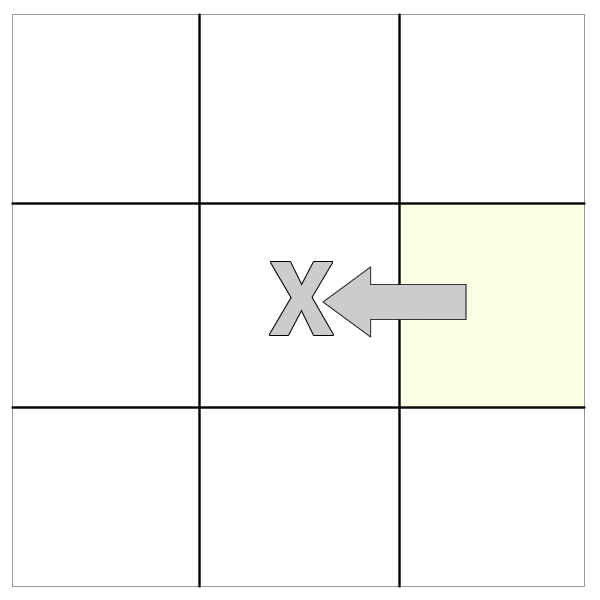
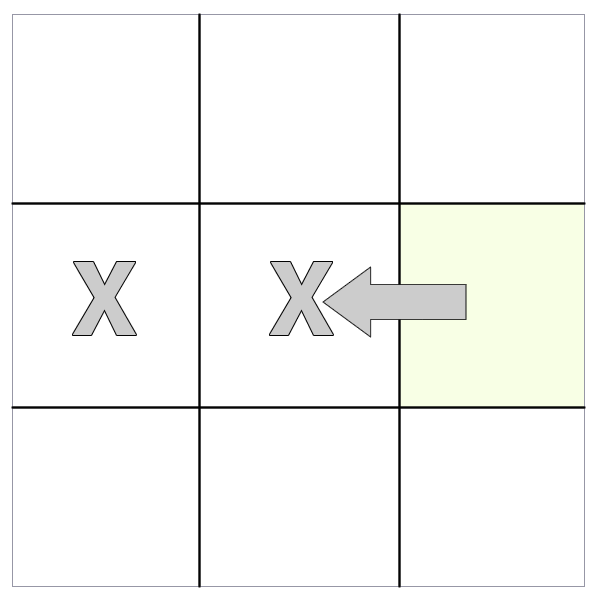
closest() and find()
Some DOM traversal methods require a selector of their own. For example, the 'closest()' method will get the DOM element that matches the passed selector and is closest to the selected node (or is the selected node) within the DOM tree. It's important to note that it does this by traversing up the DOM tree, meaning it won't return any elements that are children of the currently selected node.
Unlike , which traverses up the DOM tree, traverses down. It will return any elements that match the passed selector (unlike which only returns one).
Do We Even Need jQuery?
It turns out that in the years since jQuery first came about, the browser has greatly improved in its ability to handle basic DOM traversal. In fact, under the covers, wherever possible, jQuery is just using many of these methods, meaning that, in many cases, we are replacing one line of JavaScript with one line of jQuery in our code - but with the added heft of the entire jQuery library.
Given these improvements, its fair to ask, do we even need jQuery at all for DOM traversal? Let's examine how we might replace all of the code listed above using plain JavaScript.
Selectors
Using and , we can easily replace the selectors I listed above. If you are so inclined, you could even map these functions to and you'd hardly notice jQuery was missing. Let's see how.
Here are the replacements for the four selectors listed previously.
document.querySelectorAll(".fancybutton")
//...pass!
As you can see, it's pretty much a one line of plain JavaScript for one line of jQuery replacement.
OK - So I Cheated!
...but only just a little.
Most selectors in jQuery are straight CSS selectors. Since also uses CSS selectors, the replacement is simple. However, some (like ) are jQuery specific. The following function is based upon the implementation of within jQuery and will accomplish the same thing.
for ( ; i < length; i += 2 ) {
matches.push(elems[i]);
}
return matches;
}
The method isn't complicated, but it does mean you have to call as opposed to filtering with the selector.
The above method will work for any element, but you could also, in cases where all the items are children of a particular element (which is commonly the case), replace with this one-liner:
siblings()
As with a number of the DOM traversal methods, there is no native replacement for , so we'll need to replace it with a method of our own.
Once this method is written, we'd could relatively easily replace the jQuery examples from above.
The returned elements would be the same.
parent() and parents()
There is a straightforward one line replacement for the jQuery method. The prior examples could be replaced with:
Once again, these will return the same DOM node. However, there is no simple replacement for , so we'll have to write one.
Using this method, we could replace jQuery's with our .
next() and nextAll()
There are actually numerous potential replacements for these methods (note: Thanks to Keith Clark for the tip). There is a property on Node, which you might think would work. This is the property used internally by jQuery to handle this method. However, in some browsers, this returns a blank space, which is often just there for code formatting, so a replacement needs to accommodate this.
For simplicity's sake, I decided to replace both methods with a single method but it is based upon the way it is implemented inside jQuery.
To replace jQuery's we simple call and supply the DOM node:
To replace , we simply supply the second parameter as :
However, it turns out that you can also get the next element using just specialized selectors. You can select the next element using the adjacent selector:
Or recreate using the less strict sibling combinator.
In addition, the childNode API has a property called that will eliminate the behavior of returning whitespace elements. So could be recreated as:
I have not done cross-browser testing on these methods but, according to MDN, the support is excellent (though I am not sure why jQuery doesn't use it).
prev() and prevAll()
As you would expect, this is similar to the replacement. We utilize (as jQuery does) but handle situations where it returns spaces.
Once again, our replacement for the prior examples is simple. For , we pass just the DOM node:
And for we pass the secondary argument as :
As with , the childNode API has a property called that will eliminate the behavior of returning whitespace elements. So could be recreated as:
Again, I have not done cross-browser testing on this method, but according to MDN, the support is excellent (though, again I am not sure why jQuery doesn't use it).
closest() and find()
As you hopefully recall from earlier in the article, and took additional selectors as arguments. There is also no direct replacement for but we can easily achieve one using the method.
This method is pretty simple and works just fine. Simply pass the selected node as the first argument and the selector as the second and we have a replacement for the jQuery example:
The problem is that support is not yet universal and is often prefixed (in fact, the actual spec appears to be and not but it hasn't been implemented that way in most browsers). So, if you need to support legacy browsers and need to use , things get complicated.
Maybe You Do Need jQuery!
While replacing any individual method wasn't overly complex, we've now written six new methods just to replicate the basic jQuery examples from earlier in the article. Our methods may work, but overall its nowhere near as robust or easy to use as jQuery. So maybe it turns out that we do need jQuery after all!
...or do we? Someone must have thought of new approaches to DOM traversal in the eight years since jQuery arrived. Perhaps there a better, more modern way to do this that leverages of some of the browser API improvements.
DOM Traversal with HTML.js
Nearly a year ago, I wrote about a library called Voyeur. It dared to take a completely different approach to DOM traversal by allowing you to chain together DOM nodes in a very intuitive and comfortable fashion. For example, rather than selecting a node via , you would simple use something more like . This seemed to make complete sense in many ways.
And then it didn't. The author of Voyeur, Adrian Cooney, abandoned the project because, as he explained it, it could never achieve the performance needed to actually use it in a production application (he specifically cited the performance around as the primary issue).
But the story didn't end there. Nathan Bubna picked up where Voyeur left off and created a library called HTML.js that worked to improve some of the issues with Voyeur.
Let's look at how this approach is different and whether it might offer a better solution.
Selectors
The replacement for the selectors from my prior jQuery example are pretty straightforward since the method of HTML.js works similarly to jQuery. Once again, the replacement for is slightly convoluted, but at least we were able to get it to a single line (well, sort of).
HTML.query(".fancybutton")
HTML.query("li").only(function(o,i){ return !(i%2); })
Arguably, however, this is not an improvement nor is it demonstrably different than jQuery.
siblings()
We can also replace jQuery's with what can be called one line of JavaScript using HTML.js. The replacement for the jQuery examples from earlier would be:
Once again, the fact that this is a single line is more of a technicality than anything else and certainly can't be called an improvement over jQuery.
parent() and parents()
Since HTML.js works with standard DOM nodes, we can rely on the standard methods provided by the browser for many functions. This means that, rather than have a method for , we simple use .
This could be considered a small improvement over the jQuery method but really isn't an improvement over the straight JavaScript examples shown previously.
However, since there is no browser replacement for , we need to implement a method for it very similar to the straight JavaScript example from before.
The only real difference here is that since we are using HTML.js, we pass a DOM node using that.
Definitely not an improvement.
WTF! Now You're Just Messing with Us!
Ok. I admit that so far, using HTML.js seems like a mix of the worst of both worlds. However, that's really because we aren't relying on its strengths and instead we're trying to fit it into a jQuery box.
Where HTML.js excels is in traversing down the DOM tree in an intuitive way using chaining of DOM elements.
The result of this would be all the table cells in the first row.

Our simple example HTML did not actually have the tags in it, but in my testing these were automatically added to the DOM (at least in Chrome) and thus were necessary.
HTML.js offers some methods to easily filter the results.
This would select the second row in the table (unlike the jQuery or straight JavaScript selectors, this is using a zero-based array).
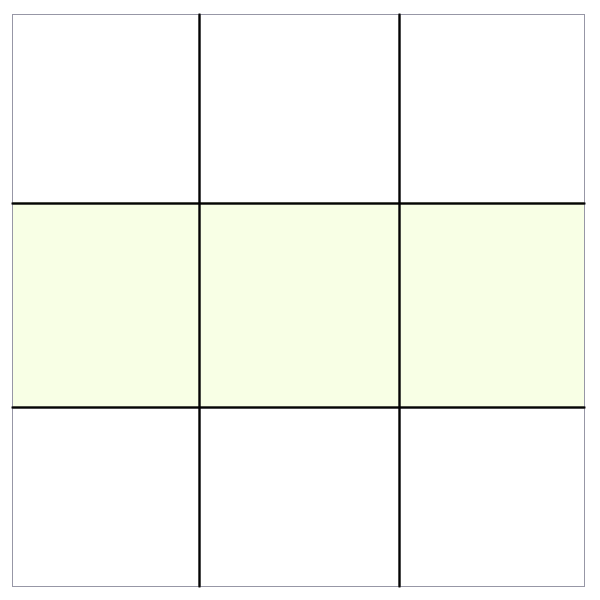
You can continue chaining as necessary to get the results you want.

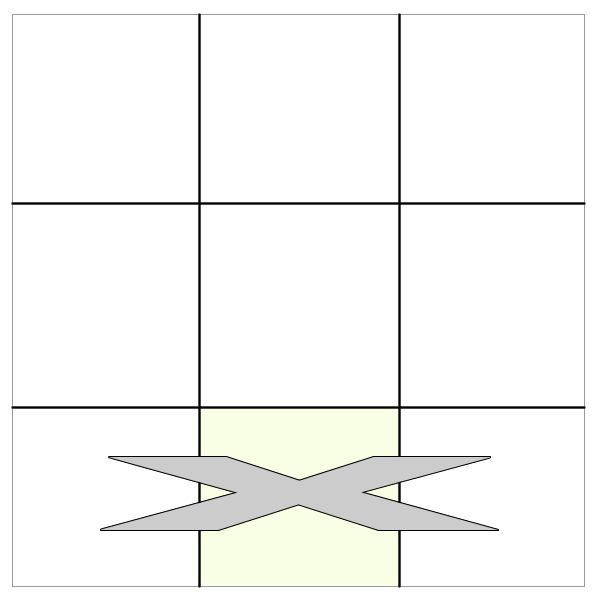
HTML.js also provides useful methods like for traversing through and acting upon the results.
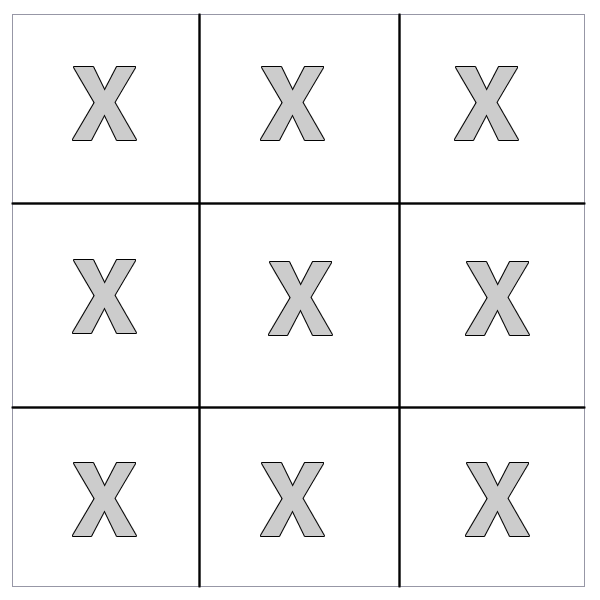
For example,the following code:
...would place an "X" inside every cell in the table.
One thing I did notice was that, while it was very easy to move down the DOM, it was much less easy to move back up. In theory, you could rely upon built-in methods like or , but as we've already covered, these offer some complications which you would still need to resolve.
Another complication is that it doesn't offer a complete set of alternatives for the jQuery DOM traversal methods we covered previously.
Still, I feel it's worth experimenting with HTML.js as at least offers a fresh perspective on the task of DOM traversal.
Wrapping Up
Based upon my experiments using jQuery, plain JavaScript and HTML.js, here are my conclusions.
- jQuery still offers the easiest and cleanest API for DOM traversal...however, jQuery might be more than you need.
- In many cases, you can replace 1 line of jQuery with 1 line of plain JavaScript...however, it's not always so easy and you may end up rewriting (and maintaining) a lot of methods.
- HTML.js offers a unique way to traverse the DOM that can feel intuitive in many cases...however, it's missing a lot of methods that you might need.
In my opinion, the net result is that most people should probably just stick with jQuery. It's API is still the most complete and the so-called "bloat" is often overstated.
This article was originally published at http://flippinawesome.org/2014/05/12/rethinking-dom-traversal/