For some very good reasons, computers aren't very good at understanding language, we can usually beat them at our most complicated games, and they have yet to prove any great new abstract theorems or make great art. But numbers are their primary domain, and counting things is one of their most basic skills. It's counterintuitive, but in modern databases, it turns out that counting is one of the most difficult things to do. When you match that with the expectation that it's simple, counting can cause a lot of headaches.
Let's take a close look at what counting means for a database, and see if we can gain some insight about how to structure applications.
To try to find some common ground, my example database maps keys to values, and supports insert, delete, and next (which can be a point query or part of a range scan). Note that you can think of values as rows in SQL or Cassandra, documents in MongoDB or CouchDB, or whatever you like; keys can be a unique identifier (like in MongoDB), or a secondary key, it won't matter for our discussion. This is most similar to BerkeleyDB's model, and Riak users should be comfortable too, except that next allows for range scans.
Simple solutions

Suppose all you want to do is count all the keys in the database right now (we can talk about ranges later). One way is to iterate over everything when you want to count it, but this takes a long time. Instead, you could cache the count somewhere, and update it with every insert or delete. That way, when you want the count, it's already computed (and if the database stores your data in a tree, you can extend this idea, caching counts on nodes in the tree, to work for range counts too). All you need to do is read that one number and return it.
This second idea seems to work really well...until you start thinking about time.
No time like the present
Notice above how I defined the problem: "all the keys in the database right now." It turns out that "now" is a difficult thing to define: do I want to know the count from when I issued the query, or should it be accurate at the instant when I get the answer back? Is there some middle ground we can strike? Do either of the endpoints even make sense? These types of questions will be central to all of our problems with counting. In fact, most problems in databases arise because "now" is a complicated idea.

To simplify a little bit, we won't think in terms of "wall clock" time (3:45PM EST), instead we'll think in "logical time." Logical time is counted in operations, rather than milliseconds. That is, we'll consider the different states the database is in, based on what has been inserted or deleted, and the whole time in between consecutive inserts and deletes will be considered one "moment" from a logical perspective, even if they're 10 minutes apart.
Isolation
If we just care about knowing what's happening in between consecutive operations, we can just put a big lock around our database, and make sure nobody is inserting or deleting while we check the cached value. This is actually what MongoDB and MyISAM do to support fast counting, but one of their biggest problems, in general, is this big lock around the database. The problem is that, to define these times "in between consecutive operations," you must serialize those operations. When the inserts and deletes are serialized, it reduces the throughput of the system to the speed of a single core, and we can do a lot better than that these days.
Things start to get interesting when you allow concurrent inserts and deletes. Now an insert might complete while the count operation is running. You need to decide what the right answer should be: should it include the insert or not? The rules for how this decision is made are collectively known as the Isolation Level of the database.
There are many valid isolation guarantees a database can provide, and some databases offer a few choices to the application. Choosing the right isolation level is typically a tradeoff between expressive power given to the application and a speedup from a reduction in complexity in the database. The default isolation used for queries in InnoDB, TokuDB, and TokuMX is known as repeatable read (or "mvcc" in TokuMX). Repeatable read isolation gives the strongest guarantees for queries, but can be done without taking any locks.
Suppose you start with an empty database, and send two inserts that get scheduled like this:
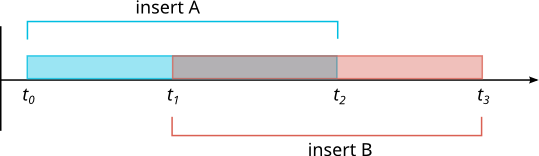
Surely, before t the count should be 0, and after t it should be 2, but in between, there is some confusion. Should we count A's insert? Should we count B's?
In repeatable read isolation, when a count operation (or any query) begins, it determines a "snapshot" of data that the query is allowed to see Any operations that finish after the query starts are "hidden" from that query. Therefore, if the count comes before t, it should be 0 and if it comes between t and t, it should be 1.
The way this works is by maintaining some "MVCC" (multiversion concurrency control) information about the relative order of inserts and deletes in relation to the queries that need to understand what they should be able to read. This information is encoded alongside each key and value, so that concurrent inserts and deletes that are modifying different keys in the database can proceed without conflicting with each other. Range query operations look at each piece of MVCC information as they read keys, to determine which value, if any, to read.
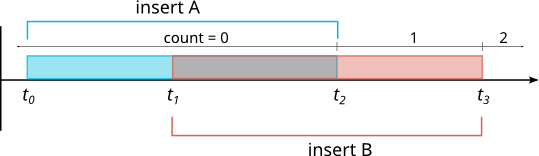
In this concurrent system, our original solution still works, we can just iterate over all the rows our count operation is allowed to see. However, we can't cache this value. Suppose three operations arrive: a count A, an insert B, and then a count C (after B completes):
According to repeatable read isolation, A should see 0 and C should see 1. So if we were to cache a value for the count, we'd have to cache both 0 and 1, with some MVCC information, after t in this case. This would be just like having an extra key in the database where the count is stored, except that every single insert and delete would have to update it. The way we get concurrency in the system is by having separate inserters and deleters work on unrelated keys. If all of them had to update this one count value, they'd contend with each other on updating it, which would destroy the benefit of concurrent writers.
In fact, even with weaker isolation properties like read committed, we'd still get memory contention if every inserting or deleting client tried to update this cached value, and that would slow the database down.
For distributed database systems, the old isolation models tend to be problematic, but there is ongoing research into new isolation models that would apply equally well to counting as to normal multi-item or range queries.
Applications
The result of all this is that in databases that allow concurrent writes, counting is roughly as expensive as a normal range query because it really does need to iterate over all the keys, to see which of them are visible to the query. Optimizations like caching a single count for the database, or caching intermediate results of counts over ranges don't work well because they cause contention among writers and therefore reduce throughput.
It's possible to make a concurrent database behave, for counting, like a database without concurrency, by maintaining a cached count on your own, and updating it with each transaction. With this architecture, you'll be introducing a lot of contention on that value, and the database will almost certainly slow down.
In your applications, you should always think about the cost of each operation, and remember that different databases implement some operations much differently than others.