The annual State of the Climate report, issued by the National Oceanic and Atmospheric Administration for last year, stated: "In 2012, the contiguous United States (CONUS) average annual temperature of 55.3°F was 3.2°F above the 20th-century average, and was the warmest year in the 1895-2012 period of record for the nation." As a statistician, my immediate question was: "How sure are we of that?" As it turns out, surprisingly sure.
Statistics permeates all of science and society. Climate science is no exception. For example, climate models produce projections of future climate. Features of these projections, such as increasing annual minimum temperatures in northern regions of the world, can be sought in observed data. Statistical methods are available to do this.
Climate is not weather. As Robert Heinlein put it, "Climate is what you expect, weather is what you get." Consider rolling a die. If it is fair, a six comes up in 1/6 of the rolls in the long run. If it is loaded toward the side showing the one (which is opposite to that showing the six), it will come up six more often.
We can think of the changing climate as a die that slowly is getting more and more likely to roll sixes and weather as the outcome of a particular roll of the climate die, with a six representing extreme temperatures. So, comparing weather data directly to climate models is not quite the right comparison. Statisticians have long known how to compare the probabilities of dice rolls to observations, and this knowledge is now directly used to compare climate models to weather observations, in spite of the differences between the two types of data.
Analysis of data over geographic space and time requires specialized statistical tools, since usually there is a tendency for nearby locations and nearby time-points to move up and down together. If one fails to take this so-called dependence into account in the statistical analysis, one is easily fooled into thinking, for example, that trends are more accurately determined than is really the case. And since trends are the bread and butter for scientists who study changes in climate, it is essential to deliver an accurate statistical analysis.
Global climate models are very large. Therefore, it is not possible with present-day computers to run these models on a fine-enough scale to be able to use them to study local effects (at the county or city scale) of a changing climate. Instead, one often runs regional models that use global model values around the region and then uses a finer-scale model inside the region.
Does it matter which global model one uses? The North American Regional Climate Change and Assessment Program is designed to compare different combinations of regional and global models. Statisticians have tools that allow researchers to study the combined effects of global and regional models on outcomes without having to run all possible combinations of global and regional models, thus saving considerable amounts of precious computer time.
The analysis yields estimates of the uncertainty in the regional model output. This output, or regional projection, is likely to be used to make local planning decisions. If that planning is done assuming that the output is a definite value, rather than a range of possible values, serious problems can arise. For example, in the year 2100, the estimated sea-level rise at Olympia, the capital of Washington, under a medium scenario is 13." This is an average, and if planners protect downtown based on this average and something rather higher happens, their efforts to protect the downtown area from flooding may be in vain.
When scientists use the word "uncertainty," they do not mean "lack of knowledge." Rather, they mean a way of specifying how precisely they know something. To answer the question about how precisely they know that a given year is the warmest on record, we need some kind of specification of the uncertainty in each yearly continental U.S. temperature.
We do not measure U.S. temperature directly. Rather, we measure temperatures at many stations. Different stations have been operating for varying lengths of time. Measurements have been made at different times of day. Some stations have moved or changed instruments. All this must be taken into account when combining these measurements into a continental U.S. average (such a combination is another statistical problem for which there exist well-established methods). So, for each year, scientists have calculated confidence intervals (a range of numbers with 95 percent probability to cover the true value) for the yearly continental U.S. temperature. The narrower this range, the more certain we are of the actual value.
My undergraduate student, Tae Yen Kim, and I jointly developed a statistical method to assess the uncertainty of the rankings. Based on data from 1897 through 2008, we found that the probability that 1998 -- the warmest year on record for this time period -- actually was the warmest, is about two-thirds, but 1998 could have been as low as the fourth-warmest year ever. Instead of 1998, one of the years of 1921, 1934 or 2006 may have been the warmest with a probability of one-third.
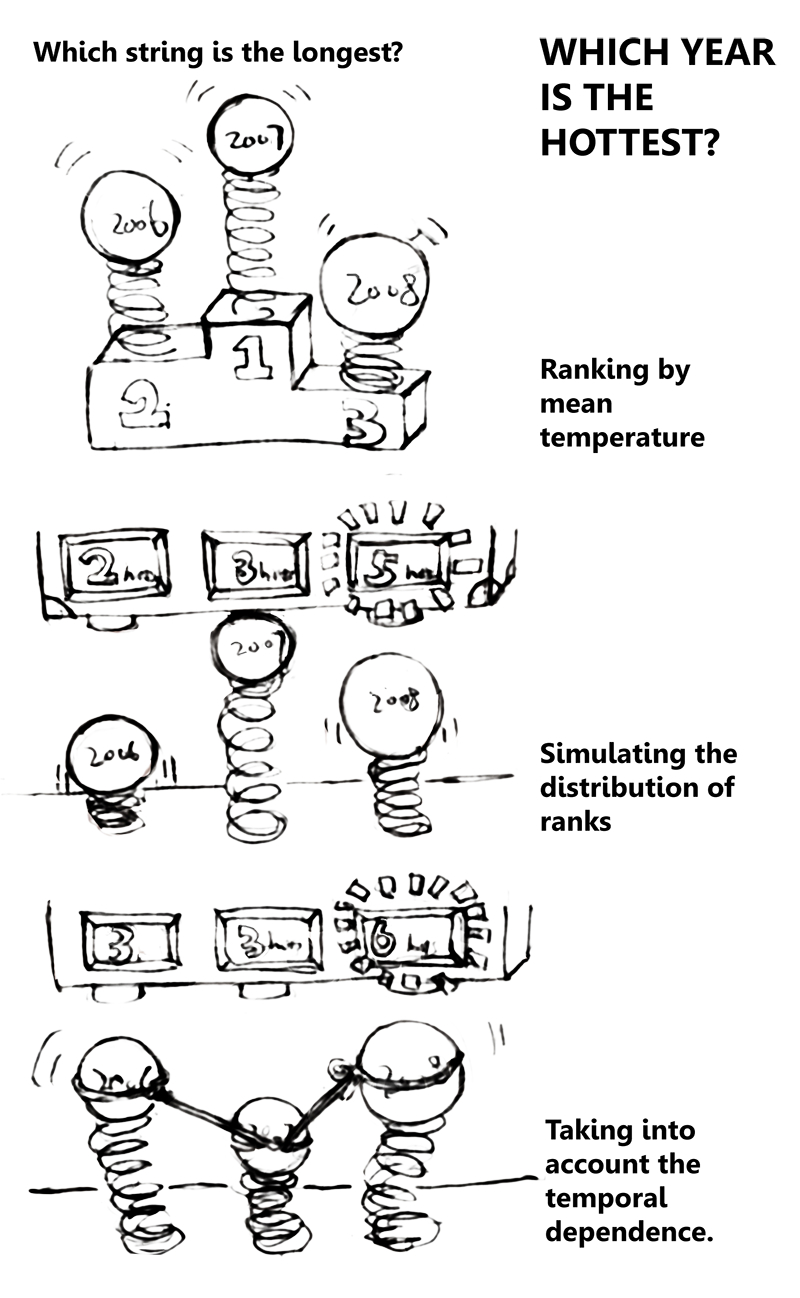
So what about 2012? When we originally wrote our paper, the data for 2012 were not yet complete, but are now available. We have applied our statistical method to the series including the years 2009 through 2012. This process involves simulating 100,000 series with the same uncertainty characteristics as the historical record. In each of these 100,000 series, 2012 was the warmest! In other words, there is so little uncertainty in the ranking that we can say -- in spite of the uncertainty in the actual value of the 2012 temperature -- that we know 2012 was the warmest year in the historical record of continental U.S. temperatures.
Peter Guttorp is professor of statistics, quantitative ecology and resource management and urban design and planning at the University of Washington in Seattle.