[This post was co-authored with Jelte Wicherts]
In his well-read blog post, originally titled "Why Black Women Are Less Physically Attractive Than Other Women", psychologist Satoshi Kanazawa from the London School of Economics (LSE) concluded that he had found that African American women were "objectively" less attractive than European American, Asian American and Native American women. The immediate and far-reaching responses to his controversial conclusions led Psychology Today to first change the blog's title and later to retract it altogether.
Within a few days after the post appeared on the site, a firestorm ensued. Bloggers from all over the world expressed their outrage at the post. Many people's responses were emotionally charged, and rightly so. Many African American women, who must experience discrimination all their lives, were upset and hurt. Other critiques attempted to be analytical, but didn't address the key issues, or attacked the entire field of evolutionary psychology because of one member of the discipline (see my thoughts on that here). The largest student organization in London (representing 120,000 students) demanded Kanazawa's discharge from LSE. According to its spokesman, LSE has started an internal investigation into the blog, although the LSE spokesman stressed the academic freedom of its researchers.
We agree that scientists should not be sacked for making impolite statements that may offend people. However academic freedom does not entail the right (1) to misinterpret data and (2) to ignore empirical findings that go against stated claims.
We retrieved the data from Add Health on which Satoshi Kanazawa based his conclusions to see whether his results hold up to scrutiny. Add Health is a study conducted on a nationally representative sample of adolescents in grades 7-12 who have been followed up to adulthood. The study includes many, many variables (over 8000 in the publicly available data sets alone), including measures of social, economic, psychological and physical well-being. When we first opened the dataset, we were overwhelmed with variables! (One thing we can thank Kanazawa for is even raising this question in the first place, as we probably would not have normally ever looked at the variables he did. Additionally, it must be noted that with so many variables, there are bound to be many statistically significant results in the dataset simply due to chance [2].)
Once we finally located the relevant variables, we conducted the relevant analyses and here's what we found:
1. Kanazawa mentions several times that his data on attractiveness are scored "objectively." The ratings of attractiveness made by the interviewers show extremely large differences in terms of how attractive they found the interviewee. For instance the ratings collected from Waves 1 and 2 are correlated at only r = .300 (a correlation ranges from -1.0 to +1.00), suggesting that a meager 9% of the differences in second wave ratings of the same individual can be predicted on the basis of ratings made a year before [1]. The ratings taken at Waves 3 and 4 correlated between raters even lower, at only .136 -- even though the interviewees had reached adulthood by then and so are not expected to change in physical development as strongly as the teenagers. Although these ratings were not taken at the same time, if ratings of attractiveness have less than 2% common variance, one is hard pressed to side with Kanazawa's assertion that attractiveness can be rated objectively.
The low convergence of ratings finding suggests that in this very large and representative dataset, beauty is mostly in the eye of the beholder. What we are looking at here are simple ratings of attractiveness by interviewers whose tastes differ rather strongly. For instance, one interviewer (no. 153) rated 32 women as looking "about average," while another interviewer (no. 237) found almost all 18 women he rated to be "unattractive." Because raters differ strongly in terms of how they rate interviewee's attractiveness and because most of them did numerous interviews and ratings, this source of variation needs to be taken into account when testing for average race differences in ratings of attractiveness. Kanazawa does not indicate that he did so.
2. Kanazawa interprets his findings in terms of adult attractiveness yet the majority of his data were based on the ratings of attractiveness of the participants when they were teenagers. If many of us (including the authors of this post) were judged throughout our lives based on our physical attractiveness as a teenager, a lot of us would be in trouble!
Add Health currently has four "waves," or phases. Here is a chart of the four waves and the age groups of the four waves:
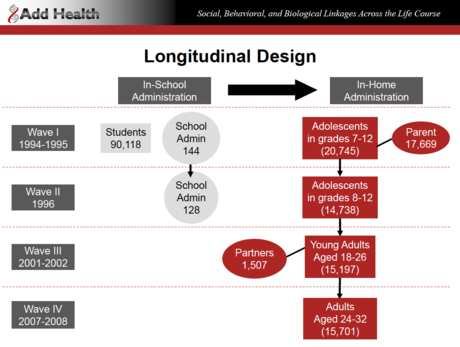
Note that only Wave IV actually consists of "Adults." In fact, the range of ages for Wave I and Wave II is 12-22, with an average age of about 16 for both waves.
Imagine the scenario. Adult researchers (unfortunately we couldn't find out information about the actual interviewers themselves) went into the homes of these participants and rated their own subjective view of the physical attractiveness of the study participants on a scale from 1 to 5 (ranging from "very unattractive" to "very attractive"). For Waves I and II in particular, the ratings couldn't possibly (we hope!) be referring to ratings of the sexual attractiveness of these kids. So discussions of this topic using data from the dating website OK Cupid really aren't appropriate here.
Only in Waves 3 and 4 were the participants old enough on average (M = 22.2, SD = 1.9 and M= 29.00 SD = 1.8, respectively) to be actually called "women" and "men" instead of girls and boys. If one looks at the data from the waves (3 and 4) in which all of the interviewees reached legal adulthood, the pattern of results no longer supports Kanazawa's main conclusion.
In Wave 3, we did find a very slight difference in attractiveness ratings in favor of European women, but this is effect is no longer significant after we take into account the random variation due to the raters.
However, only data from Wave 4 is relevant for the issue that Kanazawa wants to address simply because this is the only Wave consisting of adults (they were collected when all of the participants were adults aged 25-34). Unfortunately, Kanazawa does not include presentation of these Wave 4 results, despite the fact that he uses Add Health data in most of his studies and these data have been available for over a month.
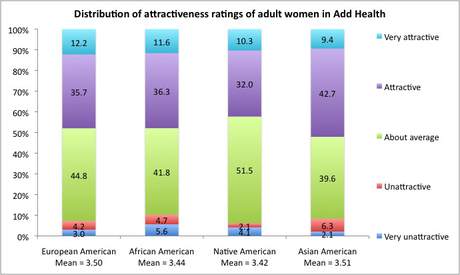
Focusing just on Wave 4, it is obvious that among the women in the sample, there is no difference between the ethnicities in terms of ratings of physical attractiveness. Differences in the distributions for females when tested with a regular (and slightly liberal) test of independence is non-significant and hence can be attributed to chance (Pearson's Chi-Square=15.6, DF=12, p =.210). Here's the graph that shows the distribution of ratings (in percentages) for 1564 European Americans, 553 African Americans, 97 Native Americans, and 96 Asian American females (with arithmetic means below each group):
We also analyzed the data for the men in the sample and the same wave and found that the race group differences for the males was just significant (Pearson's Chi-Square=21.2, DF=12, p = .048), with males showing a slightly higher overall attractiveness rating than the other ethnicities (Note: this result is not statistically sound though as it does not take into account dependency of the datapoints due to the use of the same raters). Here's that graph:
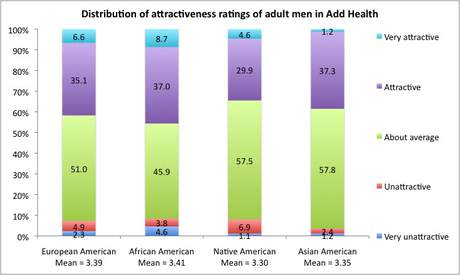
Since this very minor difference did not show up at Wave 3, we wouldn't make much of it.
Kanazawa claims to be only interested in the "hard" truths on human nature. And the truth of the matter is: As adults, black women in North America are not rated less attractive by interviewers of the Add Health study, which is one of the most nationally representative samples ever available for investigation.
Note that the data could have come out any which way, and no matter how it turned out we would have reported what we found. We do think this is an interesting and important topic of investigation. Other rigorous peer-reviewed published research (involving a much less representative and smaller sample of the United States) has shown statistically significant mean differences in attractiveness ratings based on ethnicity.
It is our view though that such research should be held to a higher standard than other research topics both in scientific rigor and presentation (see here for a similar argument). This should be so especially for topics that could potentially cause harm and suffering to individuals within a particular group. Science doesn't operate in a vacuum. Rigorous science collection and responsible science reporting is essential not just for the progress of science but also for the betterment of society (isn't that the point of psychology?).
Even if good, rigorous research does eventually show that black women are rated differently, on average, in relevant characteristics (although it's highly unlikely considering the representativeness of this dataset), there may indeed be implications for racism. The way to combat racism though is not to ignore it (see here for a related argument) but understand how and why it develops, entertaining the full range of potential causal explanations, from the biological, to cultural learning, to bio-socio-cultural learning.
Earl Hunt and Jerry Carlson offer 10 principles of design, analysis, and reporting that ought to be considered carefully when doing or evaluating research on group differences (they focus on differences in intelligence but their principles equally apply to the investigation of differences in attractiveness). The full paper can be downloaded here and we hope can offer a set of guidelines for further researchers who decide to conduct research on this topic as well as bloggers who decide they want to communicate these findings to a general audience.
As the researchers put it:
"When scientists deal with investigations that have relevance to immediate social policies, as studies of group differences can have, it is the duty of scientists to exercise a higher standard of scientific rigor in their research than would be necessary when the goal of the research is solely to advance exploration within science itself. We do not, at any time, argue that certain knowledge should be forbidden on the grounds that it might be used improperly. We do argue that when there is a chance that particular findings will be quickly translated into public debates and policy decisions it is the duty of the scientist to be sure that those findings are of the highest quality."
Kanazawa does not follow these guidelines in all of his publications. For instance, in a paper on race differences in IQ he not only committed several theoretical errors, but also failed to consider alternative explanations. Incidentally, in that particular paper he also assumed that the earth was flat!
Science, when done properly, is self-correcting. Bad science and interpretations are replaced by better quality science and more sensible and accurate conclusions. If you would like to analyze the Add Health dataset yourself, you can! You can request your very own copy of the dataset here. We look forward to further sensible discussion about these important topics, which impact importantly on the lives of many people.
You can download a fuller, more technical summary of our analysis here.
© 2011 by Scott Barry Kaufman and Jelte Wicherts
[1] Some may quibble with our use of the word "meager" here to refer to a correlation of .30. We should note that these correlations are not the typical correlations found in differential psychology (e.g., IQ with some personality variable) but rather an analyses of inter-rater agreement. On the basis of the crosstabs, the Cohen's Kappa of Wave1-Wave2 for women is .196. According to Landis and Koch this should be interpreted as "slight agreement". Kappa for Wave3-Wave4 is .099-- even worse.
[2] Our reasoning here is taken from the standard Pearson-Neyman decision theory. If one assumes the null hypothesis to be true for, say, 1000 potential tests, then 50 of these tests are expected to be significant at alpha=05. If we conclude on the basis of p