The morning after a good night for the predictions we made with my poll-averaging model...
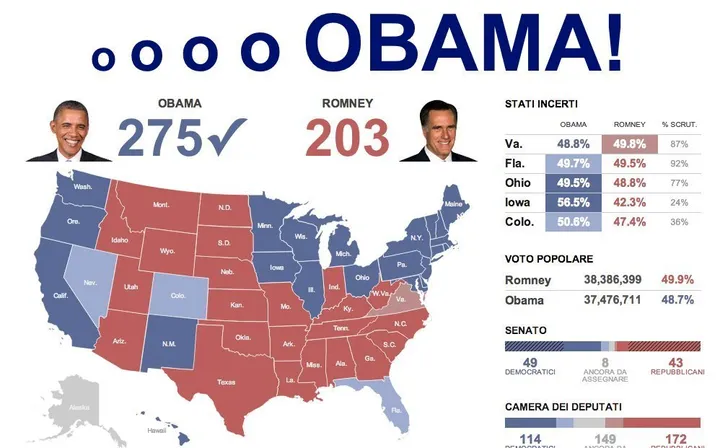
The headline: If Florida stays in the Obama column, we will have called each state correctly: 51 out of 51, and the Obama Electoral College count bang on 332.
We're not alone on this. Drew Linzer at Votomatic, Nate Silver at FiveThirtyEight, Sam Wang... it looks like we've all hit it.
And think about that for a moment. The "quant triumph" here is more about the way we've approached the problem: a blend of political insight, statistical modeling, a ton of code and a fire hose of data from the pollsters. Since at least four or five of us will claim 51/51 (subject to FL) this cycle, it's not "a Nate thing." It's a data-meets-good-model, scientific-method thing. Mark Blumenthal has expressed similar thoughts here.
The final national popular vote estimate from my model was 50.86 percent, two-party for Obama. This came out of the final run I made after publishing 50.8 percent and for assessing accuracy I'll be bound by that 50.8 percent estimate. Right now (9 a.m. Eastern) AP is saying 51.1 percent, Obama two-party, so we're off by 0.3 percentage points at this stage, a figure that I expect to see rise over the course of the vote count.
State-by-state point predictions: See the graph, below, with predictions on the horizontal axis, actual counts (using the recent data from AP) on the vertical axis, all in two-party terms. If the predictions were perfect, the points in the graph would lie on the 45 degree line.
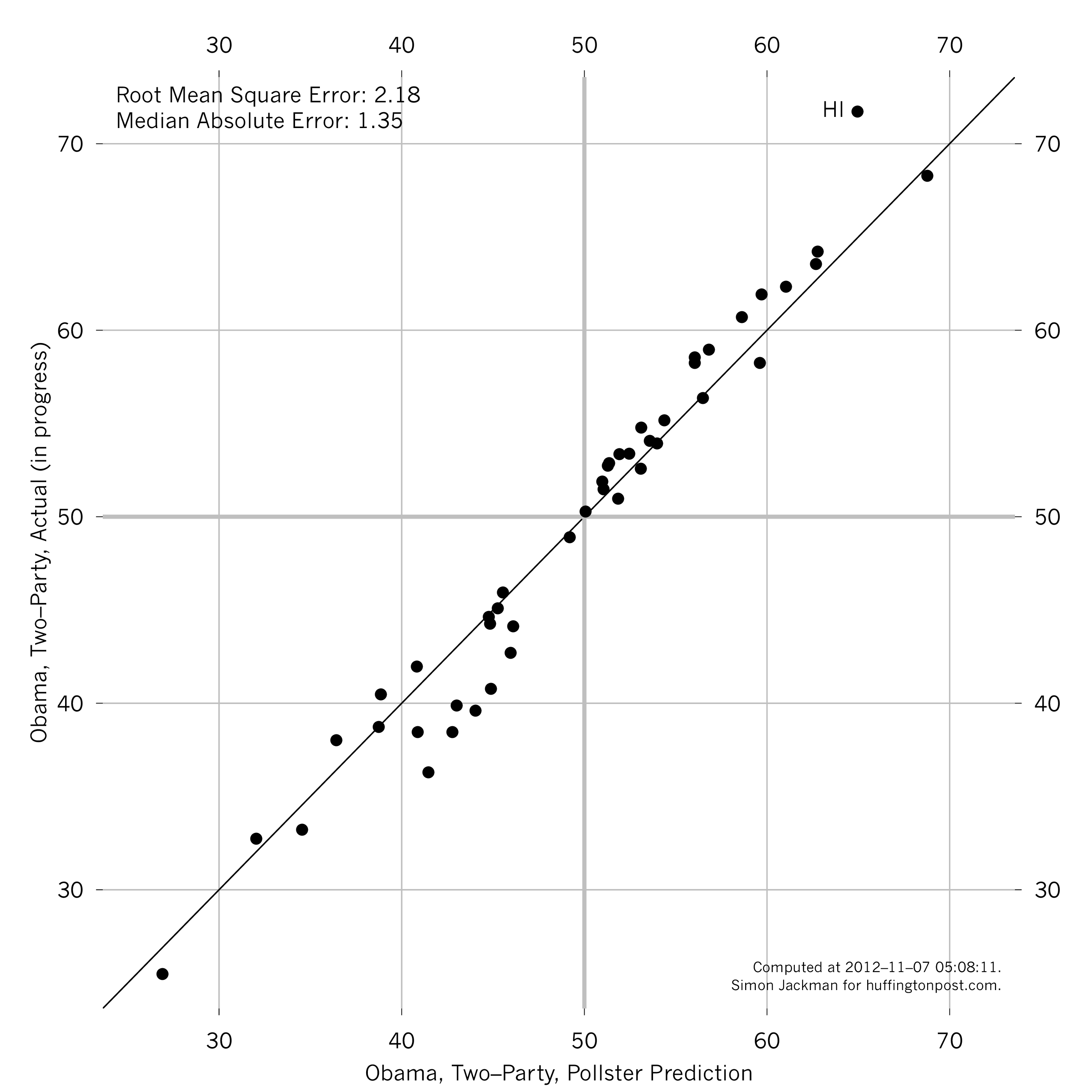
We underestimated Obama support in Hawaii by a substantial margin, enough to degrade the overall performance of the point predictions. RMSE is 2.18 points, the median absolute error is 1.35 points (the MAE measure down-weights the Hawaii error). Not too shabby, and I'm happy to have bigger misses in the non-competitive states. Indeed, given where the balance of the polling was (more of it in the swing states!), any model relying on the polls will tend to do better in those more competitive, more frequently polled states.
If we compare the state-by-state predicted probabilities of Obama winning with the actual outcomes, we obtain the following graph. We generally assigned low (high) probabilities of Obama wins in the states Obama lost (won). A corollary of having called all states correctly is that we never assigned Obama win probabilities lower (greater) than 50 percent in states that Obama won (lost). Furthermore, my model produced uncertain forecasts in relatively few cases (e.g., Florida, Virginia, North Carolina), which is a measure of its predictive power.
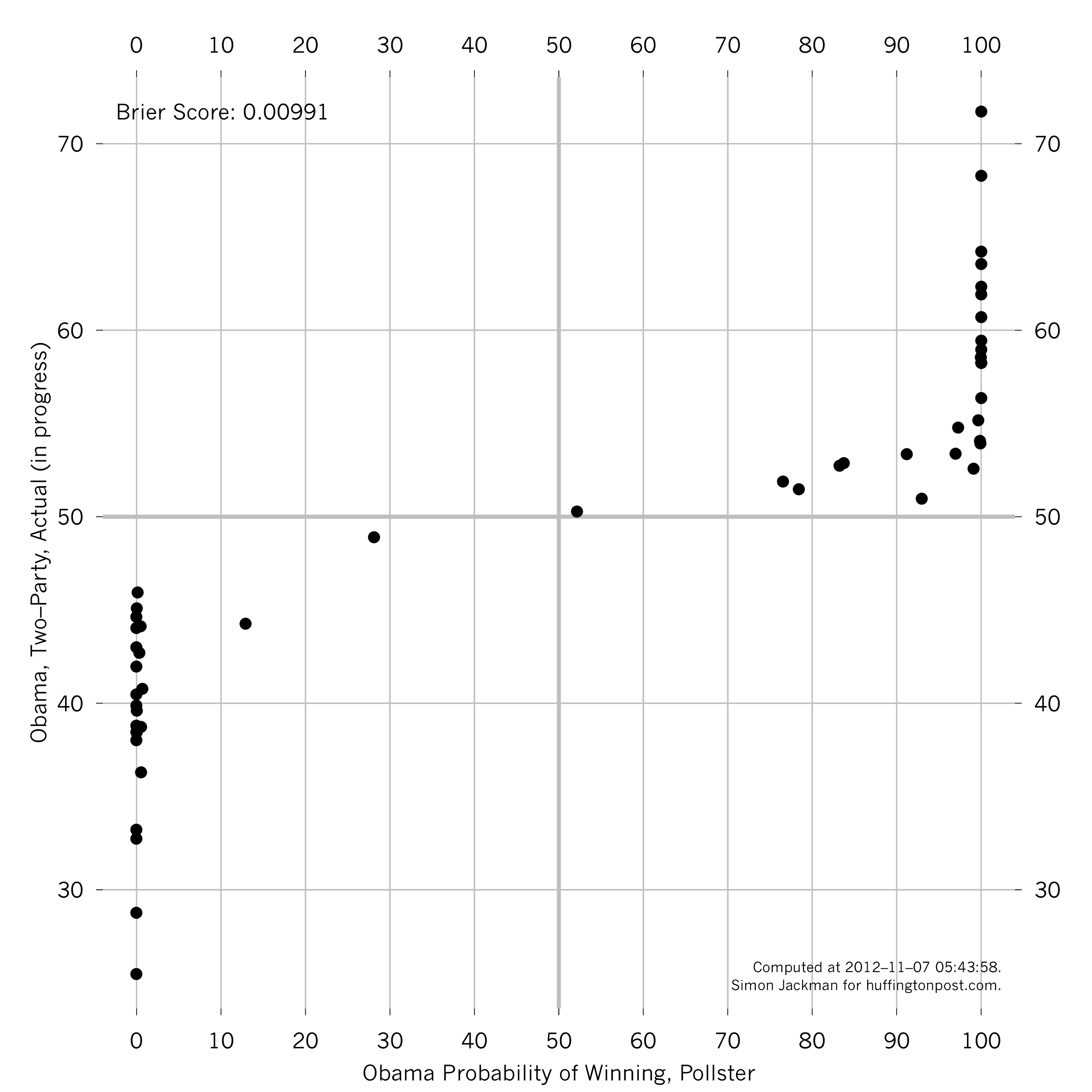
A widely used measure of predictive performance is Brier scoring with lower scores indicative of better performance. The score for my predictions is 0.0091; a prediction rule that said every states was a 50-50 proposition would have a Brier score of 0.25. We'll see how that stacks up against other models out there.
Critically, these forecast probabilities were just that -- forecast probabilities -- not model-based, poll-average probabilities of an Obama lead in the polls. The forecast probabilities hedge a little, reflecting uncertainty about the mapping from a poll average to an election outcome (as I explained in an earlier post). The probabilities we were displaying on the maps on the Pollster dashboard during the campaign were the more confident, "probability of Obama lead" quantities, not the forecast probabilities shown here. An even more impressive Brier score would result from plugging in the "probability of Obama lead" numbers, but we made a clear distinction between these two quantities; it wouldn't be right to "unhedge" now that we've observed the election results.