This is the third installment of a trio of blogs on social media analysis (SMA), and it provides an example of how SMA works -- after all, a picture is worth a thousand words. The first provided an overview of social media analysis, followed by the second that focused on technological innovations within SMA. The tough part of this blog was to find a real, timely dataset that I could use to demonstrate social media analysis of a brand without "picking on" a particular industry or product therein, and yet was something every reader would understand. I decided to use the recently released documents captured during the Osama bin Laden raid because it timely appeared in a blog on The Huffington Post on May 3 and piqued my interest. It is a bit of a stretch to align documents to/from bin Laden as social media posts, but if we think of bin Laden as a brand -- albeit a terrorist -- then the data gleaned from the documents can be used to describe how SMA works on social media related to any brand, especially with traditional brand attributes, as opposed to attributes like equipment, organizations, locations, persons, etc.
The tool that I chose for to perform the SMA example is Cloud Text Analytics (CTA), which is a cloud-scale indexing and analysis application that identifies (extracts) entities (person, locations, weapons, vehicles, etc.) and their relationships as well as provides needed document analysis such as clustering, duplicate identification, disambiguation and correlation, etc. CTA is developed by Orbis Technologies, Inc., the company for which I also serve as Chief Technology Officer, so this limits any negative feedback should I misrepresent one of the SMA products. Although CTA is not software-focused on the SMA market, it provides the capabilities needed to highlight the key aspects of SMA software covered in my previous blogs.
The corpus released contained 17 documents in Arabic (175 pages) with manual English translation (197 pages). One of the innovations mentioned in the earlier blogs is that of applying language services within natural language processing (NLP) to extract entities in the native language. Since there existed some irregularities in the translation, as documented in the document corpus guide, we used CTA to extract from the English translation, but language services remains a key innovation in SMA tools. An SMA tool should, at a minimum, be able to extract the key entities, such as the brand name, and any key related facts. Below is a screen shot of CTA showing an extracted document and its key facts based on a search for our brand name -- Osama bin Laden.
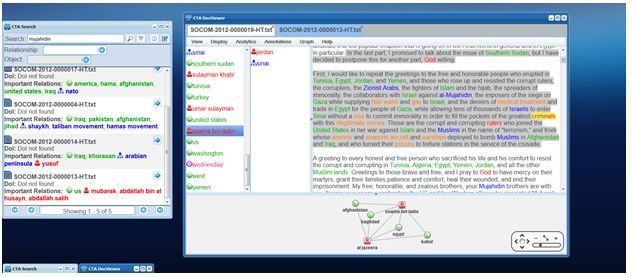
CTA extracts the key entities (objects of interest) from the text and provides a small graph of our brand at the bottom of the document that lists the key facts. These key facts are also highlighted in the left panel within the area labeled "Important Relationships." This allows a user to find the key facts and relationships in a post without having to read the full text. The brand graph can be added across multiple documents such as in the image below. Another key indicator in CTA is the percentage of new content, which is an indicator of cut-and-paste or reposts that you might often find about your brand. The document icons are shaded blue depending on the amount of new content; all documents are approximately 100 percent except Document 17 in this screenshot, which reuses much content from Document 16. This might lead us to not have as much confidence in the issues raised by this post; i.e., a post that is an exact re-post is less likely to be trusted as a post that contains similar information but is the author's words.
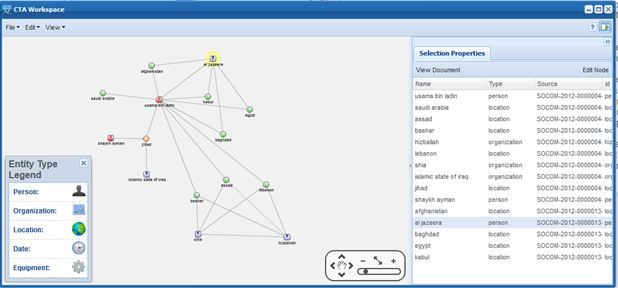
It is important to anchor the brand graph to the source of data as is the case above; e.g., data about Al Jazeera and Osama bin Laden is found in Document 13, but not Document 4, which contains information about the relationship to Hezbollah. Combining facts from the different documents, which used different spellings of Osama bin Laden, provide a better picture of the key attributes of our brand.
The last analytic that I will showcase is finding similar documents. Suppose that "waging jihad" is the key attribute we are looking for in our brand -- Osama bin Laden. If we find a document that contains key facts that pertain to this, we should be able to find similar documents. The graphic below depicts this capability in CTA, and provides indicators that show the size of the current document (orange), the similar document (blue), and the level of overlap in relationships (very high) between the two documents.

Another key SMA feature that would help improve the brand analysis is sentiment analysis, since there are expressions of anger, dissatisfaction, etc. throughout the corpus. However, the key features depicted above show how to highlight key facts, build a graph of the brand based on multiple posts, and to find similar documents that might suggest a trend. SMA tools help automate this work.
SMA has to have a human-like component to interpret the conversations between one blogger to another, a Facebook message to a site, or a tweet. This was a topic of an article I co-authored with Alan Morrison, editor of PWC's Technology Forecast, called "Natural Language Processing and Social Media Intelligence: Mining insights from social media data requires more than sorting and counting words." Morrison and I argued that when NLP technologies for social media intelligence are used well, they serve as a more targeted, semantically based complement to pure statistical analysis, which is more scalable and able to tackle much larger data sets.