
How do you explain machine learning to a child? originally appeared on Quora - the knowledge sharing network where compelling questions are answered by people with unique insights.
Answer by Daniel Tunkelang, data scientist, search/discovery expert, led teams at LinkedIn and Google, on Quora.
I'd pick a universally accessible binary classification problem: learning which foods are yummy and which are yucky.
We want to teach a computer to recognize which foods are yummy and which foods are yucky. But the computer doesn't have a mouth or any way of tasting the food. Instead, we need to teach it by showing it examples of foods ("labeled training data"), some of which are yummy foods ("positive examples") and some of which are yucky foods ("negative examples"). For each labeled example, we also provide the computer with ways to describe the food ("features").
Let's make this more concrete. You might want to pick examples more catered to your child's tastes.
Some positive examples, labeled yummy: chocolate ice cream, pizza, strawberries.
Some negative examples labeled yucky: anchovies, broccoli, Brussels sprouts.
In a real machine learning system, you'd want more training data, but three positive example and three negative example should be enough to communicate the concept.
Now we need some features. Here are four features for our example: sweet, salty, crunchy, vegetable. Note that these are binary features: each food is assigned a value of "yes" or "no" for each feature.
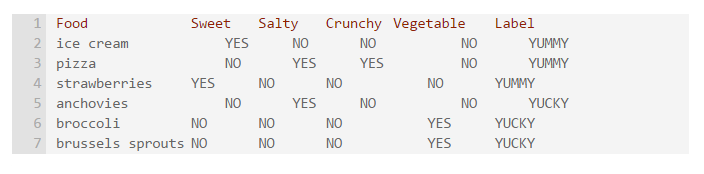
Now that we have our training data, it's the computer's job is to learn a formula ("model") from it. That way, when the computer encounters a new food, it can use the model to decide whether the food is yummy or yucky.
One kind of model is a point system ("linear model"). For each feature, you get assigned a certain number of points ("weight") if it's a YES but no points if it's a NO. The model then adds up the points for a food to get a score. The model has a cut-off: if the score is above the cut-off, the model decides that the food is YUMMY; if the score is below the cut-off, the model decides that the food is YUCKY.
For example, the model might assign a weight of 3 for sweet, 1 for salty, 1 for crunchy, and -1 for vegetable. That would result in the following scores:

Our weights make it easy to pick a cut-off: all of the positive examples have a score of 2 or higher, while all of the negative examples have scores of 1 or lower.
We won't always be able to find weights and a cut-off that classify all of the examples correctly. And even if we do, we might end up with a model that works for our training data but doesn't work so well when we give it new examples ("overfitting"). What we want is a model that is right most of the time in the training data but still works well on new examples ("generalizes"). Usually, simple models generalize better than complicated models ("Occam's Razor").
We don't have to use a linear model. Another approach is to build a "decision tree." It's just like the game of 20 questions, where you only get to ask yes-or-no questions.
It's not hard to come up with a decision tree that always gets the right answer for the training data. Here's one that works for the training data in our example.
Is it a vegetable?
- If YES, then it's YUCKY.
- If NO, then is it sweet?
- If YES, then it's YUMMY.
- If NO, then is it crunchy?
- If YES, then it's YUMMY.
- If NO, then it's YUCKY.
Just as with linear models, we have to worry about overfitting. We can't let the decision tree get too deep. That means that we'll probably end up with a model that makes some mistakes on our training data, but it will generalize better to new data.
I've skipped the details of how we actually come up with the weights and cut-off in the linear model, or how we come up with the questions ("splits") in the decision tree. That's probably more math than the child is ready for, and too much math for some adults, too. And we haven't even touched on more sophisticated models, like feature engineering or other machine learning challenges.
Hopefully, this is enough to give a child an idea of what it means to teach a computer using machine learning.
This question originally appeared on Quora - the knowledge sharing network where compelling questions are answered by people with unique insights. You can follow Quora on Twitter, Facebook, and Google+.